
Problem:
A site contains data which is of interest to us. The data is uniformly structured and available for examination by the general public (i.e. no login required) but is not automatically accessible, i.e. viewing it requires repetitive user interaction (such as setting a date range, clicking a ‘submit’ button, etc). In addition, usually the data is not organized in a way which is suitable for our purposes or we would like to use these data in another application (e.g. a spreadsheet or in our own database, etc) and for this reason we would like to download it and convert it into some format suitable for our purposes.
Solution:
An acceptable solution would automatically generate a set of text files (one for each user interaction process as described in “Problem” above). The files will be pure text, or HTML and will contain the data we want. These files can then be further processed via standard UNIX text processing tools to isolate the data we need and convert them to some other format or deliver these data to the application of interest.
Tools needed:
- root or sudo-capable account on a Linux machine. I suppose this can also be done on Windows, in particular there are versions of Wireshark and iconv for windows. I have not tried it. Does not sound like a fun project.. 🙂
- internet access
- Browser (recommended: Firefox w/ Firebug installed)
- Wireshark network packet analyzer
- text editor (preferably one capable of column-edit mode, e.g. emacs)
- curl
- iconv
Example problem:
We will be using this site for our discussion and experiments (sending POST requests via curl and processing received data):
http://www.imoti.net/prices/stat/
The example site, imoti.net is a Bulgarian real-estate site serving buy-sell and for-rent ads from individuals, companies and real-estate agencies and also keeping statistics about average sales and rental prices.
In this example we would like to get from the site the average rental prices for a 3-bedroom apartment in the “Centre” (“Център”) area of Sofia city for the period Jan-June 2016. We want to input these data into a spreadsheet and present it as a graph for easy visualization of the rental price dynamics for that period.
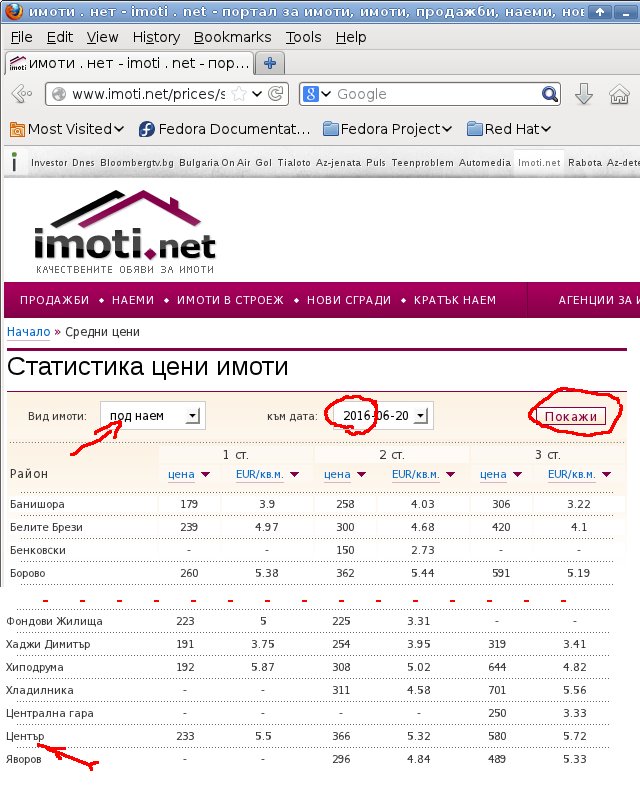
This means using the following settings on the described page (highlighted in RED on the picture):
- Вид имоти: под наем (“Property [ad] type: rentals” )
- към дата: 2016-??-?? (Date period, which is one week as we can see from the list of values which are always Mondays)
- And then clicking “Покажи” to generate the report page.
So the repetitive tasks of setting a date, clicking the button and then saving the results for the “Център” city area is what we would like to automate.
Plan:
1. Determine what is the request (POST? GET?) that the browser uses to tell the web-server to give us one of the report pages (for the particular date)
2. Scan the outgoing network stream for our request packet.
3. Determine where in the request the distinctive data occur. In our case these would be the type of ad and the date range.
4. Generate the http request via curl, telling it to save the result to a page locally.
5. Since the page uses a language other than English it may be encoded in some specific encoding (in this case CP-1251) in which case it will be necessary to use iconv to convert it into a standard UTF-8 coding for easy text processing.
6. Use grep, awk, a text editor or whatever other tool may suit your liking, to extract the data of interest from the (converted and properly encoded) text files and to import them int your favourite app (e.g. your own database or a spreadsheet)
Detailed step-by-step solution:
0. Preparation
Save the page locally (as src.html) for easy examination/grepping/etc. Test if the page is UTF-8 encoded:
$ grep "Център" src.html $
Since we know that the string “Център” appears for sure on the page and grep returns an empty set that means it can not find this (UTF-8 encoded!) string on the page which means the page is not utf-8.
So we will convert it:
$ iconv -f CP1251 -t UTF-8 src.html > src-utf8.html
Test again using the same grep command – this time grep finds several lines containing “Център” so everything is good! Replace the original src.html file with the newly generated src-utf8.html file to avoid confusion.
1. Determine request type
In the browser, using Firebug or the standard developer tools (Shift-F5 in Firefox) examine the controls which define the data we will be getting from the server, namely the “Покажи” button and the 2 drop-down lists.
Examining the “Покажи” button we can see that it fires a SUBMIT action. This means the page sends a POST request to the server when this button is pressed.
The other two controls contain lists of values easily visible in Firebug:
The drop-down list “Вид имоти:” contains the following choices:
<option value="2">продажба</option>
<option selected="" value="3">под наем</option>
<option value="4">кратък наем</option>
Note: “selected=” may appear in one of the other two options in your case, based on which one of them is selected.
The “към дата:” list contains a long list of dates formatted like this:
<option value="2016-06-20">2016-06-20</option> <option value="2016-06-13">2016-06-13</option>
Note: Upon closer examination it can be seen that the dates are Mondays, so in fact we can easily construct the list of dates using Excel, OpenOffice Calc or some other tool. Alternatively we can extract the list of dates from the html file we saved in step “0. Preparation“.
For now we will use the fact that the button fires a SUBMIT request and we will note the type of data for the two controls – this will come useful later.
2. Scan packets with Wireshark.
Fire up Wireshark. If you do not have it installed – it is free software and is available for download from www.wireshark.org/download.html.
Depending on your Linux distro you may need root or sudo access to put the network card into “promiscuous” mode to examine packets.
In the Wireshark Filter window enter:
http.request.method contains "POST"
This should be self-explanatory enough but just as a reminder – as we determined above the page is using a POST request so based on this criterion we are filtering our packets. You can see all this on the wireshark screenshot below.
Go back to the browser to fire a request from the page (i.e. press the submit button) so we can capture it with Wireshark. Sset some date e.g. 2016-06-20, set the type of ad (“под наем”) and hit the button. You should immediately see a new line (packet) appear in Wireshark, highlighted in light green. In fact there may be more than one packets generated by clicking a button on a page, examine the packets and use common sense to determine which one is the real POST request and which are noise (usually related to other elements on the page such as ads, Flash objects etc).
In this case our (real) POST packet is the one whose IP is the IP of imoti.net and which contains the string “POST /prices/stat/”.
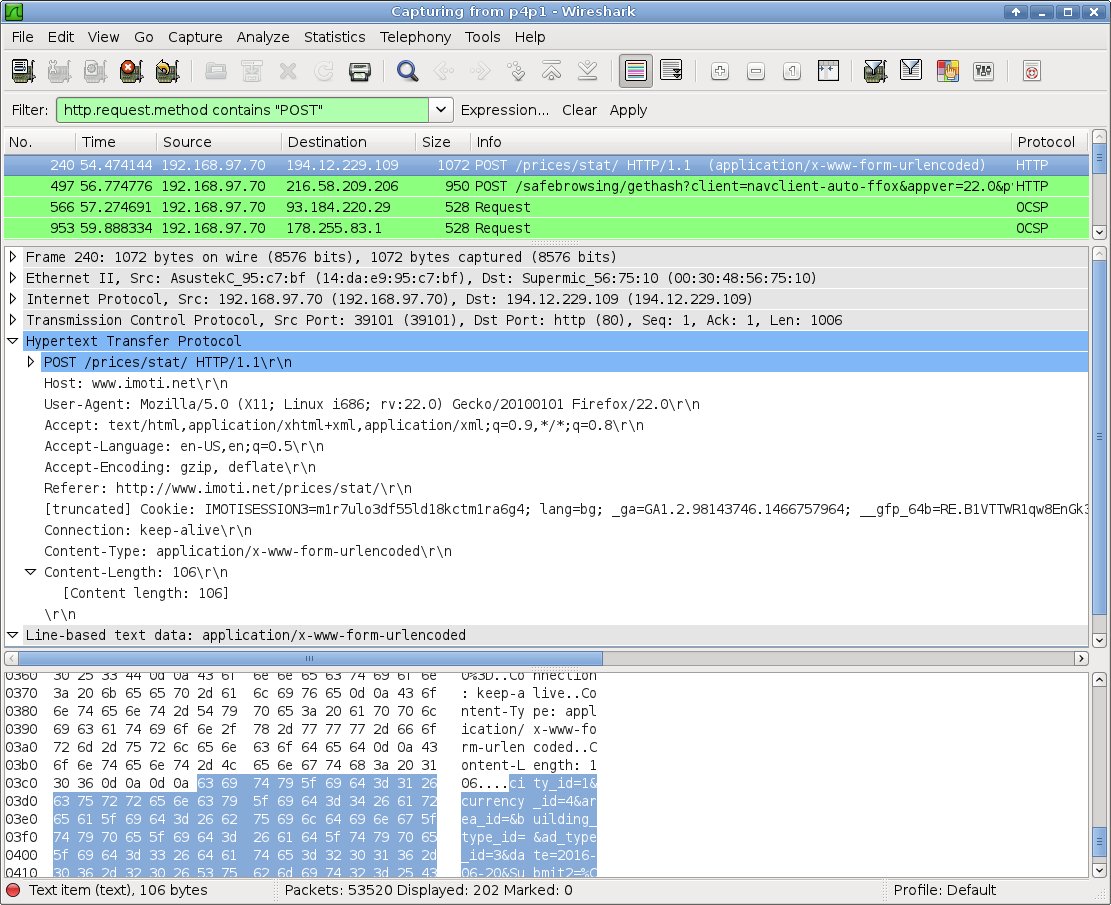
3. Look for the fields of interest inside the outgoing packet.
Examine the content of the HTTP data part:
city_id=1¤cy_id=4&area_id=&building_type_id=&ad_type_id=3&date=2016-06-20&Submit2=%CF%EE%EA%E0%E6%E8
Bingo. 🙂
Obviously “ad_type_id=3“ and “date=2016-06-20” are the key components of the request which we can modify to repetitively request data from the server. This assumption is based on our examination of the two drop down boxes – in one of them we found the dates list and in the other one we have ad_type_id=3 matching <option value="3">под наем</option>
4. curl
We can now go ahead and construct a sample POST request for curl and see if it results in correct page being fetched from the server. The curl command is given below, broken into several lines for readability.
$ curl \ --data "city_id=1¤cy_id=4&area_id=&building_type_id=&ad_type_id=3&date=2016-06-20&Submit2=%CF%EE%EA%E0%E6%E8" \ http://www.imoti.net/prices/stat \ > out-2016-06-20.html \
The first line (the –data part) defines the body of our POST request. Based on our examination of the packet in Wireshark and on curl’s syntax.
The next line is the URI where the POST request is to be sent. Again – it is constructed based on the data we see in the packet captured by Wireshark. How? Easy – we know the server (imoti.net) and we append to it the path, (/prices/stat/, taken from the POST line in the packet which gives is the complete URI.
The last line is of course the file where the output will be saved. To prepare for the automation of the process we append the date to the name of the file. This way we have an easy pattern four our output files naming scheme.
5. Is the output page encoded using UTF-8?
Given that the initial page we got from the server was not this one will most likely not be either. But lets confirm this:
$ grep "Център" out-2016-06-20.html $
Nothing. OK. Let’s convert it.
$ iconv -f CP1251 -t UTF-8 out-2016-06-20.html > out-2016-06-20-utf8.html $ grep "Център" out-2016-06-20-utf8.html <tr> ... <td>Център</td> ...
Woo hoo! We got it! 🙂
At this point writing a script which would fetch and grep/awk/sed through the data for the info you need should be a no brainer 🙂 At any rate it is a different topic, beyond the scope of this article and the author (being more than satisfied with what was accomplished so far and more than thirsty for a pint of a cold one and it being a Friday afternoon :)) has decided to leave it as an exercise for the reader.
🙂